从零开始搭神经网络。记录会比较细碎。
每次写完深度学习的东西都会觉得脑子少了一块。
可能是被网络吃了吧。
安装
Anaconda 和 PyTorch 环境
It works on my machine.
与 VS Code 协同
Python 插件会自己帮你找到配好的环境,但是终端激活和 PowerShell 配合得不太好,调了激活之后还是找不到 conda。可以把 conda 加到 PATH 里面,但这样容易污染。换成 cmd 就可以跑起来了。
基础概念
Tensor
Tensor 是一种类似矩阵的数据结构,被用来对网络模型的输入输出和参数进行编码。它的数据与 numpy 的 ndarray 使用同样的内存布局(因此可以低成本地互相转换),不同的是它可以依靠 GPU 等硬件加速计算。
初始化
可以由 Python 内置的 list 类型或 numpy 的 ndarray 类型直接构造一个 tensor 对象,也可以使用 torch.xxx_like(tensor) 构造和已有 tensor 同样形状(各个维度值的数量)和数据类型的新 tensor。(注意有些类型需要显式指定)
PyTorch 提供了几个方法用来构建拥有 trivial 值的 tensor,例如全零、全一和随机值,可以传入一个 tuple[Int] 指定形状。
属性
Tensor 有几个额外的属性:
tensor.shape指示其形状,可以用下表索引每一维的大小tensor.dtype指示其数据类型tensor.device字符串,指示其存储位置,例如 “cpu” 或 “cuda:0”
操作
tensor 默认在 CPU 上,可以通过 tensor.to('cuda') 将这个 tensor 迁移到 GPU 上运行。记得检查 CUDA 是否可用。
可以通过 tensor[<dim1>, <dim2>, ...] 来读写数据。如果要指示某个维度的全部范围,使用 : 或 ...。写入时使用单值就可以覆盖整个子维度内的值。
tensor 之间可以进行连接 torch.cat、堆叠 torch.stack 等操作。
tensor 的乘法:
- 矩阵乘
t3 = t1 @ t2t3 = t1.matmul(t2)torch.matmul(t1, t2, out=t3)
- 元素乘
t3 = t1 * t2t3 = t1.mul(t2)torch.mul(t1, t2, out=t3)
原地操作的函数会以一个下划线结尾。少用。
数据集和数据加载器
一般情况下会希望数据与训练代码解耦。PyTorch 提供了 torch.utils.data.DataLoader 和 torch.utils.data.DataSet 两个相关的类。数据集存储样本和对应的标签(包括若干个预载的经典数据集),数据加载器基于数据集实现了一个迭代器,提供更方便的访问方式。
加载数据集
自定义的数据集类需要继承 DataSet 基类并且实现以下几个方法:
__init__:初始化存放数据和标注的路径,以及它们的变换。__len__:要返回样本的个数,一般直接return len(self.img_labels)。__getitem__:根据输入的索引,从数据集获取一个样本。它需要定位样本数据并将其转换为一个 tensor,找到对应的标签分别变换后,返回一个 tuple。
使用数据加载器准备数据
数据加载器负责按批抽取数据、shuffling 和加速数据的获取。从 DataSet 构造 DataLoader 需要提供对应的数据集、batch_size 和是否打乱。
使用数据加载器遍历数据集时,每次得到一批 train_featuers 和 train_labels,分别包含 batch_size 个对应的元素。如果启用了 shuffle,遍历完所有批次后数据会被打乱。可以使用 Sampler 实现更精细的数据获取策略。
文档这里使用了一个函数 torch.squeeze(),效果是返回移除了只有一个项的维度之后的 tensor。可以传入下标来指定移除某个单项维度。
变换
变换用于将数据从原始状态加工为可供训练的形式。加载数据集时 transform 参数用于变换数据特征,target_transform 用于变换标签。torchvision.transforms 提供了一些易用的变换。
一般会把图像格式的数据变换成标准化后的 tensor,标签变换为使用独一码的 tensor(只有一个项取 1,其他取 0).前者使用 ToTensor(),后者使用 Lambda()。
ToTensor() 将一个 PIL 图像或 ndarray 转换为 FloatTensor,并将数据缩放到 $[0, 1]$。
Lambda() 接受一个 lambda 函数,文档中将输入的数值作为下标,把一个单值 1 填到一维全零 tensor 里下标对应的位置上。
构建 NN
torch.nn 包含了所有的网络模块,都继承自 nn.Module。模块可以由其他模块组成。
通过继承 nn.Module 来自构建新的 NN 类。其中,网络结构在 __init__ 里搭建,对输入数据的操作在 forward 里定义。
搭建好的网络可以使用 to() 来移动到其他设备上。直接 print() 可以查看网络结构。
直接使用 NN 对象的括号运算符传入训练数据或测试数据。不要直接调用 forward()。输出结果是一个 tensor。把这个 tensor 喂给 nn.SoftMax 就可以得到分类的概率。
这篇文章介绍了如何将网络的数据获取、训练和测试从基于 Python 标准库一步步重构成基于 PyTorch。
几个 NN 模块
未来会出一个各种经典模块的合集,当作 toolbox 来用。
nn.Flatten
将 tensor 的若干维度压平至一维,如果不指定维度区间则只保留第一维。压缩前后遍历得到的数据次序不变。相当于抽取出行主序的形式。
nn.Linear
一层神经元,定义了输入和输出特征数量,通过自身存储的权重和偏差对输入进行线性变换。
如果输入特征数量为 $m$,输出特征数量为 $n$,则一个线性层可以被视为 $n$ 行 $m$ 列的左乘矩阵 $W$ 与一个 $n$ 维的偏差向量 $\vec{b}$,对输入向量 $\vec{x}$ 做的变换则是:
nn.ReLU
Rectified Linear Unit,ReLU,整流线性函数,一种激活函数,常用的形式为 $f(x) = \max(0, x)$。
激活函数用于将一层神经元的输入非线性地映射到下一层的输出。如果使用线性的激活函数,整个神经网络就可以被简化成一个线性映射,则拟合能力非常有限。引入非线性可以提高神经网络的拟合能力。
nn.Sequential
模组的有序容器,用于快速搭建一个网络。
模型参数
可以用 YourNetwork.names_parameters() 遍历网络的各个参数。会很多。
自动微分
最常用的训练算法是反向传播(back propagation),通过损失函数的梯度与模型参数的关系来调整模型参数。
梯度计算
PyTorch 的自动微分器是 torch.autograd,可以用于对任何计算图微分。
这是一张计算图的示例:
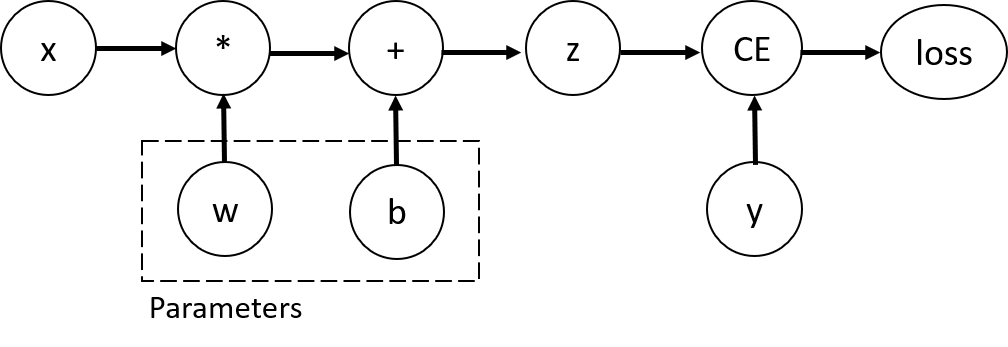
对应的 Python 代码是:
1 | import torch |
训练的目标就是寻找一组参数使网络输出与损失函数的差距尽可能小(一般是最小二乘)。存放参数的 tensor 需要传入 requires_grad=True 来记录计算梯度的操作。
调用以上代码中 loss 对象的 backward() 函数可以计算一次对 w 和 b 的偏微分,以 tensor 形式存储在它们的 grad 属性内。
backward()计算的是当前 tensor 对于计算图叶子节点的梯度。同时,启用了requires_grad的节点才会记录梯度信息。由于性能要求,计算图只能调用一次
backward(),图保存的中间值在调用此函数后会被释放。如果一定要多次调用,需要向backeard()传入retain_graph=True。
禁用梯度跟踪
启用了 requires_grad(默认都会启用)的 tensor 都会跟踪计算历史,但在前向操作时(比如测试训练好的模型)往往不需要这些信息。可以使用 torch.no_grad() 代码块禁用梯度跟踪:
1 | with torch.no_grad(): |
禁用梯度跟踪的好处:
- 把网络里的一些参数标记为冻结层
torch.no_grad()只是其中一种方法,会导致梯度无法回传- 只适用于前向计算,或者放在网络的头几层
- 可以在只进行前向计算时加快速度
计算图补充
计算图把数据(tensor)和所有执行过的操作(包括因此产生的 tensor)记录在一个由 Function 对象组成的 DAG 里。DAG 的叶节点是输入数据,根节点是输出数据。基于链式法则,通过由根遍历到各个叶子可以计算出梯度。
在前向过程中,autograd 根据对应的操作计算出结果 tensor,同时维护这些操作的梯度函数。
在后向过程中(调用计算图的 backward()),autograd 调用每个 grad_fn 计算梯度并把它们累计在对应 tensor 的 .grad 上,不断重复到叶节点。
每次调用 backward() 都会重新构建一个计算图,因此可以在模型中改变每个迭代中模型的结构和操作。
tensor 梯度和雅可比积
当输出函数是一个任意的 tensor 时,PyTorch 可以计算雅可比积而非实际的梯度。
对于一个多输出函数 $\vec{y} = f(\vec{x})$,$\vec{y}$ 相对于 $\vec{x}$ 的梯度由雅可比矩阵给出:
而 PyTorch 计算对给定的输入向量 $v$ 计算雅可比积 $v^T \cdot J$。这个步骤通过向 backward() 传入 $v$ 完成。$v$ 的形状应该和输出一样。
参数优化(训练)
有了模型和数据,下一步就是训练和测试。
在训练过程的每个迭代里,模型根据输入的 batch 给出一个输出,计算损失函数的值和偏导数,然后根据梯度来优化自己的参数。
前置代码
Hyperparameters
超参数是关于训练过程的参数,会影响模型的训练质量和收敛速度。主要有以下几种超参数:
- Epochs,遍历数据集的次数
- Batch size,每个 epoch,网络的参数更新前需要传播的样本数量。
- Learning rate,参数更新的程度,低 learning rate 会减小学习速度,而过高的 rate 会导致不可预测的训练结果。
优化循环
一个 epoch 指优化循环里的一次迭代。每个 epoch 包含一个训练循环和一个验证/测试循环。
Loss 函数
表示网络当前输出与目标输出之间的距离。训练的目标在于对训练集中的所有样本最小化这个距离。PyTorch 内置了常用的损失函数,一般研究时需要自行设计。
优化器
优化器主要的区别在于采用的优化算法。常用的比如随机梯度下降(Stochastic Gradient Descent)。优化器需要知道网络的参数集合和学习率。
训练循环主要包含三个步骤:
- 调用优化器的
zero_grad()将模型参数的梯度清零,防止累计计算(或者事后清零,都行)。 - 调用损失函数的
backward()进行反向传播,求出梯度。 - 调用优化器的
step()根据得到的梯度调整参数。
模型的存取
结果模型
可以用 torch.save() 保存模型的参数(传入模型的 .state_dict)或者整个模型(传入模型本身),并指定路径。使用 torch.load() 可以加载参数或者模型。
加载参数时需要先实例化一个对应的模型并将加载的参数传给 .load_state_dict(),之后要调用模型的 .eval() 设定成评估模式。整个模型的加载过程会自动完成实例化。
整个模型的存取基于 pickle 实现。
官方更推荐的方式是保存成比较通用的中间表达,比如 TorchScript。实际上表现不太行,这玩意好像还会解析代码的语法,但是解析能力有些差。
最好还是把状态保存下来,其他耦合的东西太多了。
1 | # Params save and load. |
checkpoint
检查点一般还要包含优化器的 .state_dict(),其中有随着模型训练而更新的参数和缓冲。此外还要保存一些超参数,比如当前的 epoch 和 loss,取决于正在使用的算法。
一般以 dict 的形式保存和读取。文件的后缀一般是 .pt。
在 GPU 上训练
目前看到的方法是每个 batch 内把数据传到 GPU 上。这个有点费 IO。
Profiling
在这里,暂时先不看。
模型的部署
使用 ONNX 来部署模型,比较简单。